Machine learning is a branch of artificial intelligence that functions to make computers able to process data so that they can recognize patterns and make predictions.
Previously we have studied the meaning of big data. In general Big Data is a raw data processing until finally producing useful insights for users. From this Big Data processing process, the core of the entire process is looking for patterns and relationships between data sets.
Data with a size that is not classified as complex or still has a “reasonable” amount, we as humans can certainly still find patterns and relationships. But what if the data we have is already very complex and large? Of course, we need the help of machines to process it, but still by maintaining our role as humans who manage the machine. This concept is what we know as Machine Learning.
Machine learning is a branch of artificial intelligence (AI) that functions to make computers able to process data so that they can recognize patterns, and make predictions or decisions based on the information obtained. Currently, the use of Machine Learning is increasingly popular in various aspects of life. This concept allows computers to learn from data without having to be explicitly programmed.
This article will discuss in depth what machine learning is, how it works, examples, and what the differences are between machine learning and deep learning.
What is Machine Learning
Before getting to know the definition of machine learning, let’s reflect on how it emerged in helping human work. Do you know that humans are actually good at understanding patterns or relationships in data. However, unfortunately humans are not good enough at processing large amounts of data (Big Data) and with fast processing times.
A Machine is considered more effective in handling this big data processing problem, but only if a machine knows how. The basic concept of Machine Learning is that if human knowledge can be combined with the speed of data processing with a machine, then the machine can process very complex data without requiring human involvement, this is a basic concept of machine learning.
So it can be concluded that, Machine learning is a concept that combines human knowledge with the speed of data processing owned by machines. The goal of machine learning is to develop computer systems to be able to learn and make decisions based on available data. This term was first introduced by Arthur Samuel in 1959, who defined it as “the ability of computers to learn without being explicitly programmed.”

Key Features of Machine Learning:
- Data-Driven: Relying on data to learn and make predictions.
- Iterative: The system learns from previous results to improve accuracy.
- Automation: Once trained, the system can work automatically without human intervention.
How Machine Learning Works
To understand how machine learning works, it is important to know its main stages:
- Data Collection
Data is the core element of machine learning. This data can be text, images, audio, or numeric data. - Data Preprocessing
Raw data often requires cleaning and transformation to make it usable by algorithms. - Algorithm Selection
There are various algorithms used in machine learning, such as:- Linear Regression
- Decision Trees
- Neural Networks
- Data Model Training
is trained using the selected algorithm to generate the model. - Model Testing and Validation
is tested with new data to assess its accuracy and performance. - Implementation
Once the model has been proven effective, it can be used to process new data.
Examples of Machine Learning in Everyday Life
Here are some examples of machine learning that we often encounter:
- Recommendation System
Algorithm used by Netflix or Spotify to recommend movies and music based on user preferences. - Bank Fraud Detection
uses machine learning to analyze transaction patterns and detect suspicious activity. - Virtual Assistants
Siri, Alexa, or Google Assistant use machine learning algorithms to understand and respond to voice commands. - Image and Video Processing
Used in facial recognition applications or photo filters on social media. - Medical Diagnosis
Algorithms that help doctors diagnose diseases based on patient data.
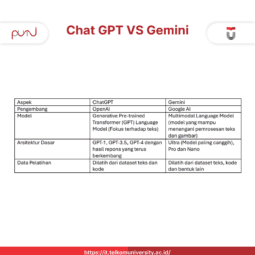
Difference between Machine Learning and Deep Learning
Although machine learning and deep learning are both part of AI, they have fundamental differences. Here is a review:
| Aspect | Machine Learning | Deep Learning |
| Definition | A branch of AI that uses algorithms to learn from data. | A subset of machine learning that uses a more complex neural network. |
| Complexity of Algorithms | Simple algorithms such as regression or decision trees. | Using deep neural networks . |
| Data Requirements | Can work with smaller amounts of data. | Requires large amounts of data for high accuracy. |
| Processing Speed | Faster with simple computing. | Requires GPU to process large data. |
| Application Examples | Recommendation system, price prediction. | Facial recognition, natural language processing (NLP). |
Machine learning is better suited for applications with limited data and light computing needs. Meanwhile, deep learning excels in processing large and complex data, such as recognizing patterns in images or sounds.
Types of Machine Learning
1. Supervised Learning
This method involves training a model with labeled data. For example, predicting the price of a house based on its size and location.
2. Unsupervised Learning
Does not require labeled data. This method is often used for clustering, such as identifying customer segments.
3. Reinforcement Learning
This method involves agents learning by trial and error to achieve a specific goal. An example is the development of AI for games such as chess.
Teknik Machine Learning
According to sources from [1] there are four (4) machine learning techniques that are often used in processing and digging data, among others:
Classification
Classification is a supervised learning technique that functions to classify data into relevant and previously learned categories. This classification process involves two main steps:
- The system is given labeled training data to build an understanding of different data categories.
- The system is then given new, unlabeled, similar data to classify. Based on its understanding of the training data, the algorithm will classify the unlabeled data.
An example of the application of Classification techniques is filtering spam emails.
Clustering
Clustering is an unsupervised learning technique that divides data into certain groups based on the similarities in the properties of each data in each group. This technique does not require pre-determined categories, but new categories will be generated from the grouping of data.
Clustering techniques are widely used in Data Mining to understand various characteristics of existing datasets. Examples of clustering applications are grouping unknown documents, grouping customers based on similar product purchasing behavior.
Outlier Detection
Outlier detection is the process of identifying data to determine the differences in significance or inconsistencies of data in a dataset. This machine learning technique is usually used to detect anomalies, abnormalities, and deviations that can produce insights such as opportunities or risks that need to be anticipated. Outlier Detection itself uses a supervised learning and unsupervised learning approach .
Examples of the application of Outlier Detection are in medical diagnostic systems, fraud detection, network data analysis, and sensor data analysis.
Filtering
Filtering is the process of finding relevant items from a set of available data. This filtering process can be done based on individual user behavior or by matching the behavior of several users. Filtering can be done with several approaches such as
- Collaborative filtering
- Content-based filtering
Examples of the application of Filtering can be found in filtering sales data based on preferences, ratings, purchase history and others.
Advantages and Challenges of Machine Learning
Superiority:
- Efficiency: Can process large data in a short time.
- Adaptive: Able to learn and adapt to new data.
- High Accuracy: Suitable for prediction and classification.
Challenge:
- Data Dependence: Data quality greatly impacts results.
- Complexity: Requires in-depth understanding of algorithms.
- Cost: Requires adequate infrastructure.
The Future of Machine Learning
With the development of technology, machine learning is predicted to increasingly dominate various sectors, such as:
- Transportation: Autonomous cars capable of driving without a driver.
- Finance: More accurate stock market predictions.
- Health: Discovery of new drugs through genetic data analysis.
Conclusion
Machine learning has become a key pillar in the digital era. With the ability to learn from data, this technology continues to open up new opportunities in various fields. Whether you want to understand what machine learning is or explore machine learning examples, this technology offers great potential for a smarter future.
Reference
[1] Erl, T., Khattak, W., & Buhler, P. (2016). Big data fundamentals: Concepts, Drivers & Techniques. Pearson.
Author: Meilina Eka Ayuningtyas