



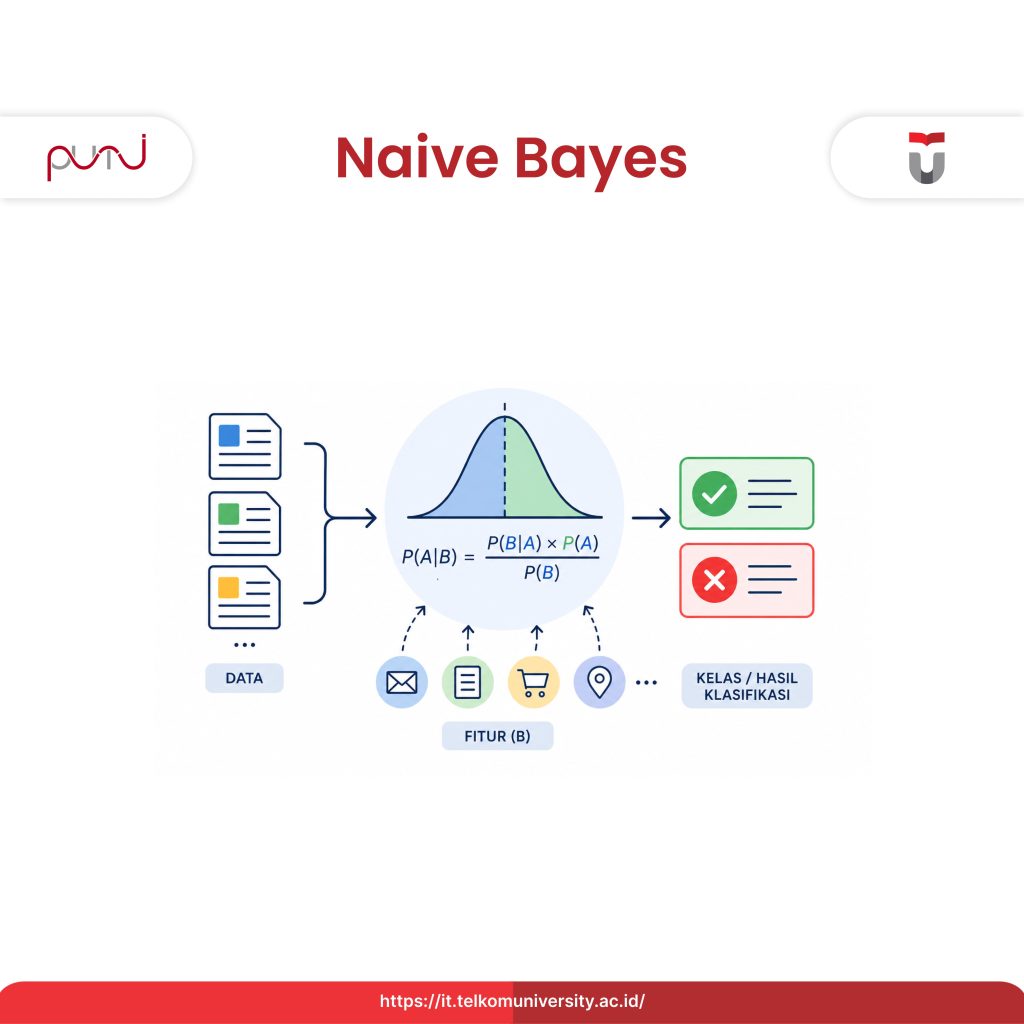
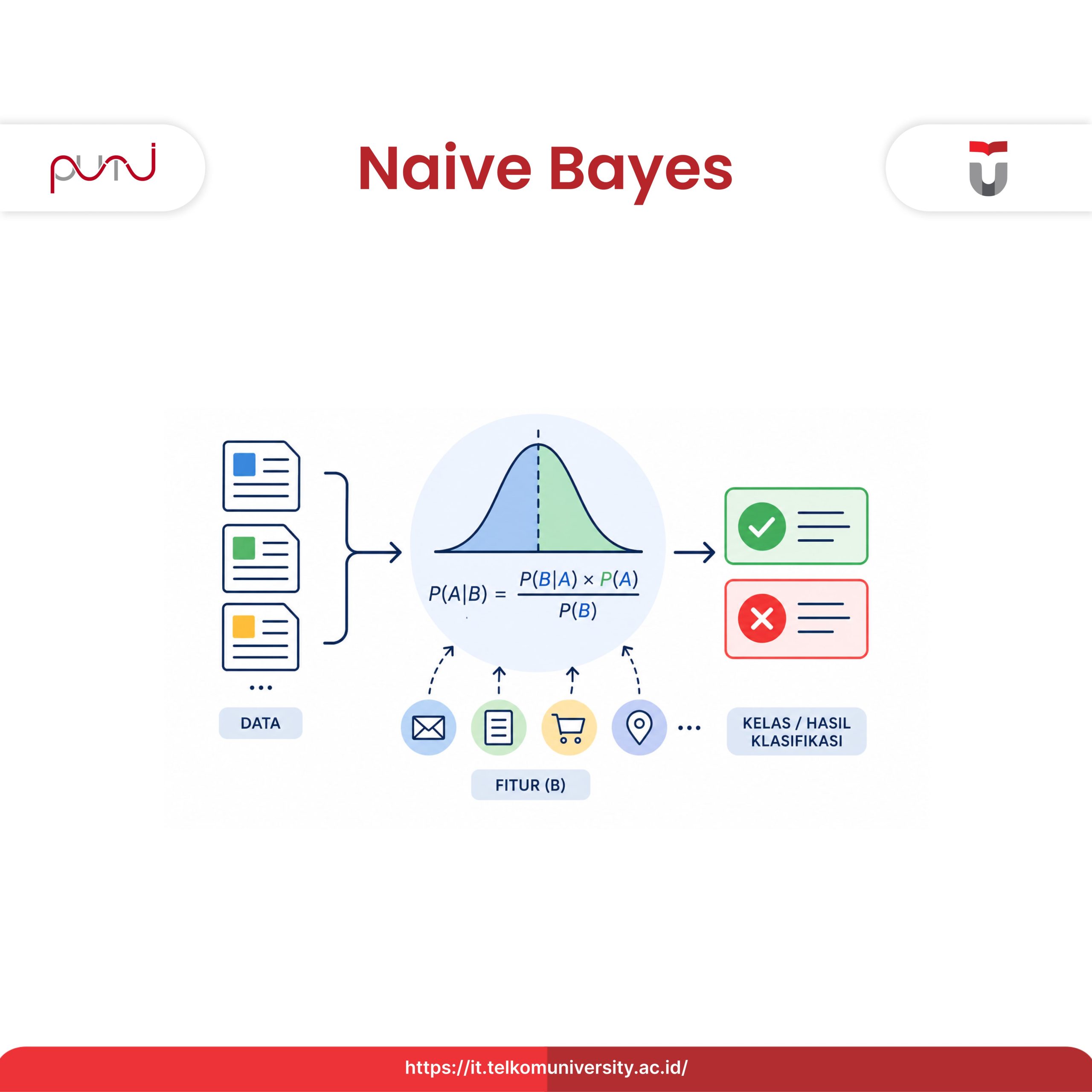
Naive Bayes adalah sebuah algoritma machine learning yang digunakan untuk mengklasifikasikan data dengan pendekatan probabilitas berdasarkan Teorema Bayes.
Pernahkah kalian penasaran mengapa email spam dapat otomatis masuk ke folder terpisah? Atau bagaimana caranya Netflix tahu film apa yang akan kalian suka? Ternyata di balik semua itu ada algoritma klasifikasi yang simpel tapi super ampuh bernama Naive Bayes.
Mengenal Naive Bayes: Ketika Matematika Bertemu Intuisi
Naive Bayes adalah sebuah algoritma machine learning yang tugasnya mengklasifikasikan data menggunakan pendekatan probabilitas. Kenapa disebut “naive” atau polos? Karena algoritma ini berasumsi kalau semua fitur itu independen—padahal kenyataannya jarang sekali seperti itu. Tapi justru di situlah keunikannya!
Algoritma Naive Bayes ini sebenarnya memanfaatkan Teorema Bayes yang diciptakan sama Thomas Bayes, seorang matematikawan dari Inggris di abad ke-18. Pada intinya, teorema ini menghitung peluang sesuatu terjadi berdasarkan informasi yang sudah kita punya sebelumnya.
Memahami Rumus Naive Bayes: Logika di Balik Prediksi
Rumus Naive Bayes pada dasarnya dari Teorema Bayes dengan rumus berikut:
P(A|B) = [P(B|A) × P(A)] / P(B)
Definisi:
- P(A|B) adalah peluang A terjadi kalau B sudah terjadi (ini namanya probabilitas posterior).
- P(B|A) adalah kebalikannya, peluang B terjadi kalau A sudah terjadi (likelihood).
- P(A) adalah peluang A terjadi secara umum (probabilitas prior).
- P(B) adalah peluang B terjadi secara umum (probabilitas marginal).
Kalau diterapkan untuk klasifikasi, A itu kategori yang ingin kita prediksi, sedangkan B itu fitur-fitur dari datanya.
Baca juga: Apa Itu Chat GPT? Memahami Teknologi AI di Balik ChatGPT
Tiga Varian Naive Bayes Algorithm yang Perlu Diketahui
Naive Bayes algorithm memiliki tiga varian yang disesuaikan dengan jenis datanya:
1. Gaussian Naive Bayes
Digunakan untuk data kontinu yang distribusinya normal. Sangat cocok untuk analisis data numerik seperti tinggi badan, berat badan, atau suhu. Varian ini menghitung rata-rata dan standar deviasi dari tiap kelas untuk membuat prediksi.
2. Multinomial Naive Bayes
Perfect untuk data diskrit, terutama dalam pemrosesan teks. Menghitung seberapa sering kata muncul yang dalam dokumen. Sangat cocok banget untuk klasifikasi teks seperti analisis sentimen atau pengelompokan berita.
3. Bernoulli Naive Bayes
Khusus untuk data biner yang hanya memiliki dua nilai (ya/tidak, 1/0). Sering dipakai dalam deteksi spam email, di mana kehadiran atau ketiadaan kata tertentu menjadi indikator penting.
Implementasi Praktis Naives Bayes
Kekuatan Naive Bayes yaitu pada kesederhanaannya yang efektif. Penerapannya seperti:
1. Filter Email Spam
Sistemnya menganalisis kata-kata yang sering muncul di email spam seperti “gratis”, “menang”, atau “klik sekarang”. Dari pola tersebut, email baru bisa diklasifikasikan dengan tingkat akurasi yang tinggi.
2. Diagnosa Medis
Dokter menggunakan Naive Bayes untuk memprediksi risiko penyakit berdasarkan kombinasi gejala pasien. Algoritmanya menghitung probabilitas suatu penyakit dari data pasien lain yang punya gejala serupa.
3. Analisis Sentimen Media Sosial
Perusahaan pantau opini publik dengan mengklasifikasikan komentar jadi positif, negatif, atau netral. Ini membantu brand memahami persepsi konsumen dan menyesuaikan strategi pemasaran mereka.
4. Sistem Rekomendasi
Platform streaming memanfaatkan Naive Bayes untuk menganalisis preferensi user dan merekomendasikan konten yang sesuai berdasarkan histori tontonan.
5. Deteksi Fraud
Bank dan fintech menggunakan algoritma ini untuk identifikasi transaksi mencurigakan dengan menganalisis pola perilaku seperti lokasi login, frekuensi transaksi, serta jumlah transfer.
Keunggulan Naives Bayes yang Menjadikannya Pilihan Populer
- Efisiensi Komputasi: Tidak butuh dataset pelatihan yang sangat besar dan prosesnya cepat.
- Mudah Diimplementasikan: Kodenya simpel dan gampang dipahami bahkan untuk pemula sekalipun.
- Serbaguna: Bisa handle data secara kuantitatif maupun kualitatif.
- Robust terhadap Data Hilang: Nilai yang hilang bisa diabaikan tanpa mengganggu perhitungan secara signifikan.
- Skalabilitas Tinggi: Cocok untuk dataset besar dengan banyak fitur.
Baca juga: Machine Learning: Konsep dan Perbedaannya dengan Deep Learning
Keterbatasan dan Cara Mengatasinya
1. Zero-Frequency Problem
Kalau ada fitur yang tidak pernah muncul dalam data training untuk kelas tertentu, probabilitas prediksinya menjadi nol. Solusinya pakai teknik smoothing seperti Laplace smoothing yang menambahkan nilai kecil pada tiap probabilitas.
2. Asumsi Independensi
Pada kenyataannya, fitur-fitur itu sering berkorelasi satu sama lain. Tapi menariknya, riset menunjukkan Naive Bayes tetep kasih hasil bagus meskipun asumsi ini dilanggar.
3. Ketergantungan pada Data Historis
Kualitas prediksi sangat bergantung pada seberapa representatif data pelatihannya. Oleh karena sangat penting memastikan dataset yang digunakan cukup komprehensif dan terbaru.
Penutup
Naive Bayes membuktikan bahwa sesuatu yang simpel itu tidak selalu berarti kurang powerful. Dengan asumsi independensi yang “naif” sekalipun, algoritma ini mampu memberi prediksi yang akurat dan efisien dalam berbagai aplikasi praktis. Dari filter spam sampai diagnosa medis, dari analisis sentimen hingga sistem rekomendasi—Naive Bayes terus memainkan peran vital dalam ekosistem machine learning.
Untuk data scientist pemula, memahami Naive Bayes sebagai langkah fundamental dalam mempelajari algoritma klasifikasi yang lebih kompleks. Sedangkan untuk praktisi berpengalaman, mengoptimalkan Naive Bayes tetap jadi skill berharga untuk menyelesaikan masalah klasifikasi dengan cepat dan efektif.
Di era big data dan artificial intelligence seperti sekarang, kemampuan menentukan prediksi yang cepat dan akurat jadi kunci kesuksesan bisnis. Naive Bayes, dengan segala kesederhanaan dan keefektifannya, akan terus menjadi senjata ampuh bagi setiap data scientist.
Referensi
- Putro, A. S. (2020). Penerapan metode Naive Bayes untuk klasifikasi pelanggan. TIKomSiN: Jurnal Teknologi Informasi dan Komunikasi, 8(2). http://dx.doi.org/10.30646/tikomsin.v8i2.500
- Fakhri, M. R., & Asro, A. (2023). Perancangan klasifikasi algoritma Naive Bayes pada data pemilihan jurusan siswa. JTT (Jurnal Teknologi Terpadu), 9(2). https://jurnal.poltekba.ac.id/index.php/jtt/article/view/1823
- Kusrini, & Luthfi, E. T. (2019). Algoritma data mining. Penerbit ANDI.
- Vulandari, R. T. (2017). Data mining: Teori dan aplikasi RapidMiner. Gava Media.
- Prasetyo, E. (2012). Data mining: Konsep dan aplikasi menggunakan MATLAB. Penerbit ANDI.
Penulis: Dian Eka F.




